How I Made OBaI’s Agents Leaner with OpenAI Agents SDK
How I used OpenAI Agents SDK, SandboxAgent, and lazy skills to reduce context bloat in OBaI’s multi-agent system

When I first started building OBaI, I used the OpenAI Responses API directly. That was the right place to begin: one endpoint, custom function tools, MCP servers, and enough flexibility to wire the system exactly how I wanted.
It was also where I learned the first painful lesson of building agents: flexibility turns into weight fast. I was writing my own guardrails, passing every MCP server and tool definition through one route, and paying for context that had nothing to do with the user’s actual question. The system worked, but it was getting expensive and noisy.
The OpenAI Agents SDK fixed a lot of that for me. It gave OBaI a cleaner backbone for agents, tools, guardrails, tracing, state, and orchestration. The tool semantics stayed familiar, but the wiring moved into agent definitions and workflow design instead of one overloaded Responses API request.
Architecturally, OBaI follows an orchestrator-worker workflow: the Hub is the orchestrator, the specialist agents are the workers, and the Hub is responsible for routing, delegation, and final synthesis.
That architecture carried OBaI for a while. Then I hit the second wall.
As I added more specialists, the hub started getting heavy again. Not because the SDK was wrong, but because my own orchestrator prompt had become the new bottleneck: too many routing rules, too many handoff formats, too many edge cases loaded on every turn.
This post is about that second migration: moving the hub to SandboxAgent, using lazy-loaded skills, and making the agent system lean enough to keep growing.
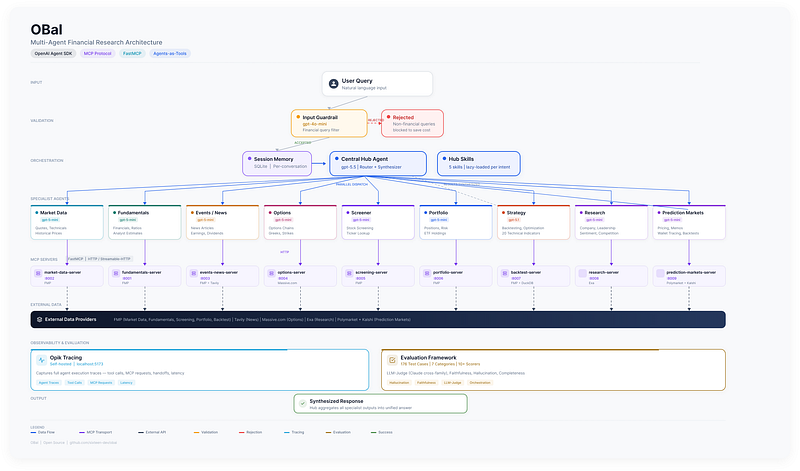
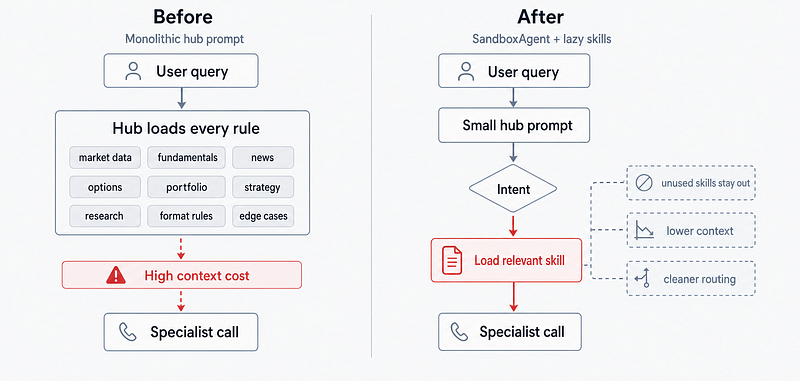
The Second Wall: One Prompt Was Doing Too Much
The hub had become a central orchestrator with a large, always-loaded prompt. Every user query paid for every rule, even when most of those rules were irrelevant.
If a user asked a simple market-data question, the orchestrator still had instructions for specialist handoffs, routing rules for unrelated domains, formatting contracts, rejection behavior, and edge-case handling from months of previous fixes.
Two problems kept showing up.
First, rules started drifting into conflict. One section would say to preserve the user’s wording exactly. Another section, written months later for a different workflow, implied that the orchestrator should normalize the request into a structured form. Both rules made sense in isolation. Together, they created inconsistent behavior.
Second, soft prompt rules did not behave like real contracts. I could tell the model not to invent a certain output shape, but if the prompt described enough invalid examples, it would sometimes invent a new one anyway.
That was the real migration trigger. The SDK changed, but the bigger issue was that the agent architecture needed to stop treating one massive prompt as the control plane.
The Sandbox Boundary Finally Made the Architecture Click
While rereading the OpenAI sandbox agent docs, one boundary finally clicked for me: the harness is the control plane, and the sandbox is the execution plane.
That distinction sounds abstract, but it was practical. My orchestrator should own routing, tool choice, guardrails, tracing, retries, and final synthesis. It should not need broad filesystem or shell access just to decide which specialist should answer a finance question.
I had actually opened a feature request asking whether lazy instruction skills could be supported on a normal Agent, without moving to SandboxAgent. The maintainer response made the direction clear: this workflow was moving toward SandboxAgent and lazy Skills(…). That convinced me to migrate the hub.
So I made the hub a SandboxAgent, but I kept its sandbox capabilities intentionally narrow. It got lazy skills because it needed modular instructions. It did not get shell and filesystem tools by default, because the hub’s job was orchestration, not workspace editing.
That was a useful mindset shift: sandbox agents are not only for agents that write files or run commands. They also give you a cleaner way to attach capabilities, keep those capabilities explicit, and avoid turning the orchestrator into a kitchen sink.
The Biggest Win: Lazy-Loaded Skills
The most useful shift was moving from one monolithic orchestrator prompt to a smaller base prompt plus lazy-loaded skills.
In practice, a skill is a focused instruction file for one kind of work. The orchestrator sees the skill names and descriptions, then loads the body only when the user’s request calls for it.
That changed the shape of the system:
- The orchestrator reads the user query.
- It decides which kind of work the query requires.
- It loads the relevant skill.
- It routes to the right specialist with only the instructions needed for that task.
This sounds simple, but it changed the day-to-day feel of the system. The base prompt became smaller. Domain-specific rules stopped colliding. Adding a new capability no longer meant editing the global orchestrator instructions and then worrying about unrelated regressions.
The important detail is that a skill description is not just a label. It is routing logic. If the description is too narrow, the model may skip the skill. If it is too vague, the model may load it too often. I started treating those descriptions like production code: small, explicit, and tested against real queries.
This is the shape of the code in my hub, simplified for the blog:
skills = Skills(
lazy_from=LocalDirLazySkillSource(
source=LocalDir(src=HUB_SKILLS_DIR),
),
)
hub = SandboxAgent(
name="central_hub",
instructions=base_prompt,
model=orchestrator_model,
tools=specialist_tools,
input_guardrails=guardrails,
default_manifest=Manifest(),
capabilities=[skills],
model_settings=ModelSettings(
parallel_tool_calls=True,
tool_choice="auto",
),
)
run_config = RunConfig(
sandbox=SandboxRunConfig(client=UnixLocalSandboxClient()),
workflow_name="Central Hub",
)The line that mattered most was capabilities=[skills]. In the SDK, passing a capabilities list replaces the defaults. That was exactly what I wanted: skill discovery without giving the orchestrator extra workspace powers it did not need.
Bigger Models Are Not Automatically Better Everywhere
During the migration, I upgraded the orchestrator from gpt-5.1 to gpt-5.5. That was the right call.
The hub is not just writing prose. It has to interpret intent, decide which skill to load, choose tools, route to the right specialist, and synthesize the final answer. That made tool-use quality more important than raw answer style.
OpenAI’s own GPT-5.5 release notes line up with what I saw in traces. On tool-use benchmarks, gpt-5.5 improved over gpt-5.4: MCP Atlas went from 70.6% to 75.3%, Toolathlon from 54.6% to 55.6%, and Tau2-bench Telecom from 92.8% to 98.0% with the original prompts. For a hub that lives or dies by routing and tool selection, those are the kinds of gains I care about.
The cost story was more complicated. OpenAI says gpt-5.5 is more token efficient than gpt-5.4, and in my own traces against gpt-5.1 it often used fewer thinking tokens. But API pricing still matters: OpenAI lists gpt-5.5 at $5 per 1M input tokens and $30 per 1M output tokens, while gpt-5.1 is $1.25 input and $10 output. Fewer thinking tokens did not automatically mean a cheaper run.
I also upgraded a specialist agent in the same pass. That was not worth it. The specialist’s job was more procedural: fetch data, run a deterministic path, evaluate the result, and return a structured answer. In side-by-side traces, gpt-5.5 and the smaller model reached the same answer. The larger one just cost more.
So I reverted that specialist and kept gpt-5.5 only where it was earning its keep: the orchestrator. This is now one of my default rules for agent systems: choose models per agent, not per application. The orchestrator, the writer, the researcher, and the data-fetching specialist do not all need the same reasoning budget.
Regression Testing Matters More Than I Expected
The most uncomfortable part of the migration was realizing how many agent failures do not show up as normal software failures.
The code can pass type checks. Unit tests can pass. The CLI can return a response. And the system can still be wrong.
The failures I cared about looked more like this:
- the orchestrator skipped a skill that should have loaded
- a user’s threshold was paraphrased into a different trading condition
- the request routed to the wrong specialist
- a specialist returned an empty payload
- an internal control marker leaked into the final answer
None of those necessarily throw an exception. They are behavioral failures, which means they need behavioral tests.
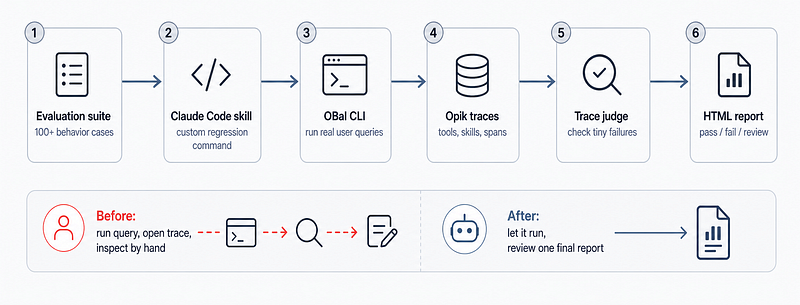
I already had more than 100 behavioral evaluation cases, but my original workflow was painfully manual. I would run one query at a time, open the matching Opik trace, inspect which tools fired, check whether the right skill loaded, look for silent failures, and decide whether the final answer was actually grounded in the specialist output.
That kind of review is useful the first few times. After that, it becomes a bad use of time. I was spending hours babysitting evaluation runs instead of building.
The simpler solution was to turn the regression workflow into an agent skill and custom command. Now Claude Code can pick cases from the evaluation suite, run each query through the real obai CLI, pull the matching Opik trace, inspect the response, tool calls, skill usage, error spans, and the small details I would normally miss, then produce a final HTML report.
The important part is that it is still black-box. It does not test a mocked orchestration path. It drives the same CLI a user would use, then grades the actual traces. I can let it run for a few hours and come back to a report instead of watching 100 traces one by one.
That changed how comfortable I felt making prompt and routing changes. The migration stopped feeling like a fragile rewrite because I had a way to see what changed across the full behavioral surface.
I still use the more traditional automated evaluation stack for critical changes: completeness, faithfulness, LLM-as-judge rubrics, strategy contract scoring, and other custom metrics. OBaI itself runs on OpenAI models, so for those checks I wanted a separate judge model and used Claude. That setup is valuable, but running all 100+ behavioral cases through an API judge every time gets expensive quickly.
Closing
The migration made one thing obvious: scaling an agent system is less about adding more instructions and more about deciding when those instructions should enter context.
The most valuable part of this migration was not just moving to a newer OpenAI Agents SDK. It was forcing the agent system to become more modular.
The old system depended on one hub prompt remembering everything. The new system depends on smaller skills, clearer contracts, and tests that look at actual behavior.
That is the lesson I would keep: agent systems do not become reliable because the prompt gets longer. They become reliable when the right instructions are loaded at the right time, important contracts are enforced outside the prompt, and changes are tested against the way the system really runs.
OBaI is open source on GitHub.