Fermix: the personal AI agent I rebuilt in Elixir
Why I rebuilt my personal AI agent as a local Elixir daemon with supervised workers, plugins, memory, model routing, evals, and bounded computer use.

Fermix started from a simple question: if tezra.io is supposed to be a lab run by agents, what should the agent running the lab actually look like?
Around the same time, I had been reading Jose Valim’s article, Why Elixir is the best language for AI, and the argument stuck with me. Agents are not just prompts calling tools. They are long-running systems with background jobs, memory, plugins, tool calls, retries, failures, and a lot of small workers doing things at the same time. That sounded less like a chatbot problem and more like an Elixir problem.
I wrote a short note about it, Elixir Might Be the Best Language for AI Agents, and started building. The first goal was not to create a big framework. It was to build a personal agent that could actually help me run my own workflow: plan work, remember context, use the tools I care about, run in the background, and stay inside boundaries I control.
That experiment became Fermix.
Why Elixir
I am not using Elixir because it makes an LLM API respond faster. It does not. I am using it because a personal AI agent is not a single request waiting on one HTTP call. It is a daemon with chat adapters, scheduled jobs, subagents, plugins, browser sessions, model routing, memory writes, streaming replies, traces, approvals, and sandboxed tools all running at the same time.
That is where Elixir fits. I wanted lightweight supervised processes, cheap subagents without framework boilerplate, and failure boundaries I could reason about. One process can own a channel adapter. Another can own a scheduled job. Another can manage a browser session. Another can run a provider route or a background worker. If one piece crashes or hangs, I want that piece isolated, logged, and restarted instead of turning the whole agent into a mystery.
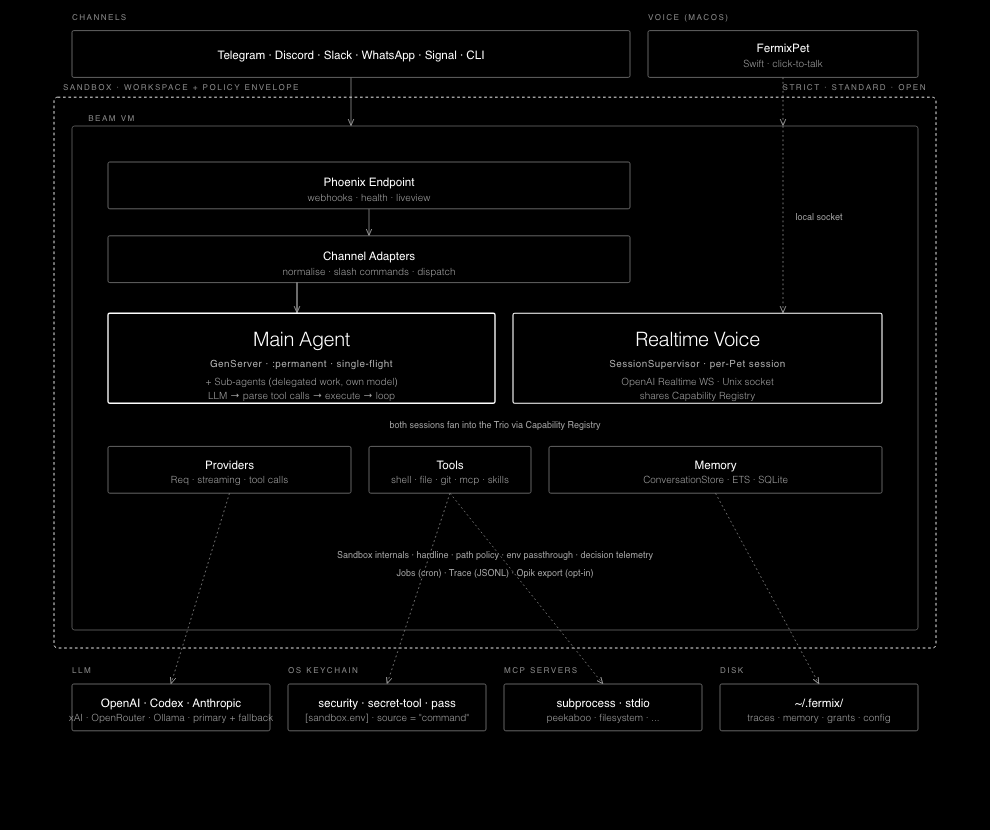
Supervision is not durability by itself, though. Fermix adds the persistence layer I need for my own workflow: scheduled jobs, run records, memory, traces, config, and prompt resources live under ~/.fermix. If the whole machine dies in the middle of a turn, that is different from restarting a failed worker. Fermix is built around durable jobs and recoverable state, not hand-wavy “let it crash” magic.
The same distinction matters for model behavior. If a worker crashes, supervision helps. If the model picks the wrong tool, invents something, leaks a refusal, or gets stuck in a loop, restarting the process does not fix it. That is why Fermix has typed failures, bounded loops, traces, tool boundaries, and evals against the real daemon. Runtime failures and semantic failures need different defenses.
I also wanted control without the maintenance tax:
- No daily upgrade treadmill
- No patching random skills or MCP servers
- No API keys scattered through environment variables
- Informants for lightweight background awareness
- Scheduled jobs with memory
- Plugins I can install and manage cleanly
- Curated memory and persona files that pick up my taste over time
- A sandbox I control, so the agent has room to work without approving every small action
One agent, many surfaces
Most assistants make me go to them. Fermix comes to the places where I already work.
It can answer from Telegram, WhatsApp, Slack, Discord, Signal, and the CLI. The channel changes, but the agent loop does not. I can ask from the terminal while coding, from Telegram when I am away from my desk, or from Slack when I am already in work mode. That sounds small until you use it every day. You stop thinking about which app has the context and start thinking about what you need done.
The same idea applies to tools. I do not want to open five apps just to move one task forward. I want Gmail, Calendar, Drive, Notion, GitHub, Obsidian, X, Slack, Discord, AgentMail, and the rest of my workflow to become capabilities the agent can use from one place. The goal is not to make the agent feel magical. The goal is to remove the parts of work where I am just acting as a clipboard between systems.
Scheduled jobs, informants, and background work
The thing I missed most from my old workflow was waking up to progress. Fermix brings that back with background work that can:
- Run scheduled jobs quietly
- Carry memory across runs
- Report back only when something useful changes
- Use informants for lightweight background awareness
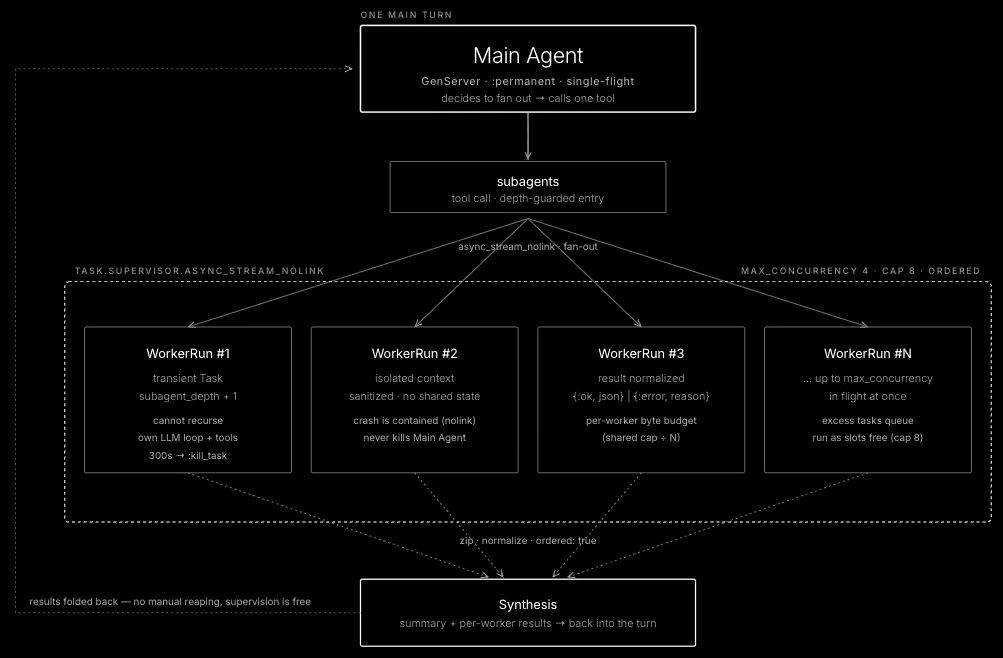
- Fan out heavier tasks through
/ultra - Keep subagents scoped so they do not become owners of my machine
That is the shape I wanted. A reminder is easy. A recurring agent that knows what happened last time, checks the right places, and summarizes only what changed is much more useful. For heavier tasks, /ultra fans work out to focused subagents and pulls the result back into one answer.
Plugins without the maintenance tax
Tools are where agents become useful, but tools are also where agent projects start to rot. I did not want to keep patching skills, wiring MCP servers by hand, or managing a graveyard of API keys in environment variables. If a capability matters to my workflow, I want it installed, configured, visible, and bounded.
Fermix treats plugins as first-class pieces of the runtime. A plugin can have its own manifest, auth, config, setup flow, allowed tools, and checks. The point is not to make plugins fancy. The point is to make them boring to live with. I should be able to add something like Slack, Discord, AgentMail, or a custom workflow capability without turning the whole agent into a fragile pile of scripts.
That also makes experimentation cleaner. I can build the plugins I actually care about, keep them close to the runtime, and avoid dragging in a large surface area just because one integration was useful.
Memory, taste, and SOUL.md
I wanted Fermix to remember more than facts. I wanted it to pick up my taste.
I am careful with phrases like “self-improving agent.” Fermix is not retraining itself on me. It improves in the practical sense: it remembers what I correct, keeps durable context in curated memory, and uses a persona file to preserve the style, rules, and preferences I actually want. Internally, that layer lives in SOUL.md. The name is less important than the mechanism. The agent can suggest changes, but I stay the editor.
That matters because most agents become annoying in the same small ways. They explain too much. They offer ten options when one is obviously right. They open with fake enthusiasm. They forget preferences I have corrected repeatedly. Fermix is built so those corrections can become part of the system instead of disappearing after one conversation.
Day one, it should be capable. A month in, it should feel more like mine.
I shipped Fermix v0.3.0 as the version I had been chasing: close enough to finally retire my OpenClaw setup, with OpenRouter, Ollama, Mistral, new plugins, and the core wishlist in place.
Computer use, with rails
Browser automation was not enough. Some workflows do not have clean APIs. Some important state lives behind auth, JavaScript, file pickers, browser sessions, or awkward UI flows. That is why Fermix is moving into computer use: not as a toy demo, but as a controlled capability inside the same local runtime.
I do not want an agent wandering around my machine without boundaries. I also do not want to approve every harmless read or tiny action. Fermix is built around a sandbox I can control, with approvals where they matter and enough room for the agent to do real work. The goal is practical agency: let it operate where it is useful, keep the risky paths visible, and make the boundaries readable.
Model routing without losing the thread
Like OpenClaw, Fermix can route across providers like OpenAI, Anthropic, xAI, OpenRouter, Mistral, and local Ollama. The main agent can have a primary route and a fallback chain, while subagents and scheduled jobs can use different models when that makes sense.
The important part is continuity. I want routing, but I do not want the agent to change personality halfway through a task because a different model was cheaper or available. The model layer should give me control, not make the agent feel unpredictable.
Evals against the real agent
The part I care about most is how I decide Fermix is safe enough to run.
Green unit tests fooled me once. They proved the pieces worked in isolation. They did not prove the workflow worked as a system. So Fermix has evals that run against the live daemon. A YAML suite describes the query, expected tool sequence, cost and latency budget, and safety gates. The runner sends a real request through fermix ask, pulls the Opik trace, and grades what actually happened.

The safety cases matter most. I do not only check whether the model said the right refusal words. I check whether the harmful thing showed up in the output or whether the wrong tool path was taken. If a critical gate fails, the release stops. It costs real money to run those evals, and that is the point. I would rather pay for a bad answer during evaluation than discover it in the middle of a workflow I depend on.
Where Fermix is now
Fermix is now at the stage I care about: it can run the workflow I built it for.
The latest public release is v0.3.1. The next release, v0.4.0, is where the newer work lands: computer use, SOUL.md self-curation, newer plugins, media paths, and the shared capability plumbing around them.
It is not a hosted gateway, not a dashboard, and not a pile of orchestration glue. It is a local Elixir agent built around the pieces I actually use:
- Supervised subagents
- Scheduled jobs with memory
- Lightweight informants
- Plugins without the maintenance tax
- Curated memory and editable taste
- Model routing
- Browser and computer-use work
- A sandbox I control
It started as an Elixir experiment.
It became the agent I use to run my work.