How To Design a Multi-Agent System with OpenAI’s Agents SDK?
Build a multi-agent “board of directors”

This post shows how to build a multi-agent “board of directors” using the OpenAI Agents SDK: one orchestrator agent coordinating seven specialist agents to produce a single GO/NO_GO verdict, top risks, next actions, and a validation experiment in a structured schema.
What you’ll build:
- An orchestrator + specialists architecture
- Parallel execution to keep latency low
- Strict JSON schemas so outputs are predictable and UI-ready
- Guardrails and optional session memory to prevent repeated advice
The Problem I Was Solving
As a solo builder, I don’t have co-founders to argue with or a board to keep me honest. I needed something that could:
- Look at the same idea from multiple angles (product, growth, risk, architecture, narrative)
- Force a clear verdict instead of “it depends”
- Return consistent outputs I could actually build UI on top of
- Remember past decisions so it doesn’t repeat the same advice next month
If you design prompts poorly, you can force any answer. The goal here is the opposite: enforce disagreement, constraints, and clarity.
How the SDK Works (Quick Overview)
The SDK has a few core concepts:
- Agent: An LLM with instructions, tools, and optional structured output
- Tools: Functions the agent can call (including other agents)
- Handoffs: Passing control from one agent to another
- Runner: Executes agents and handles the conversation loop
- Guardrails: Input/output validation before and after agent runs
Here’s the simplest possible agent:
from agents import Agent, Runner
agent = Agent(
name="Advisor",
instructions="You give honest feedback on business ideas.",
)
result = Runner.run_sync(agent, "Should I build a todo app?")
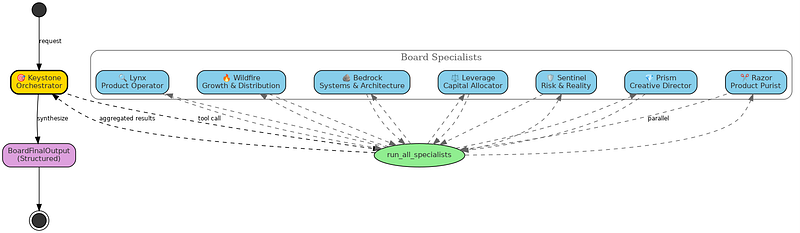
print(result.final_output)My Architecture: One Orchestrator, Seven Specialists
I built a “board” with seven specialist agents. Each one reviews the idea through a single lens and returns a structured verdict.
Feature 1: Agents as Tools
The SDK lets you wrap agents as tools, so the orchestrator can call specialists like regular functions. This simplified my code a lot because I didn’t need to build complex routing logic. The orchestrator just decides which tool to call based on the request.
from agents import Agent, function_tool, Runner
# Create specialist agents
@function_tool
async def consult_risk_agent(request: str) -> str:
"""Get risk analysis from Sentinel."""
risk_agent = Agent(
name="Sentinel",
instructions="Identify blind spots and over-optimism in ideas.",
)
result = await Runner.run(risk_agent, request)
return result.final_output
# Wrap each agent as a tool
@function_tool
async def consult_lynx(request: str) -> str:
"""Get product analysis from Lynx."""
result = await Runner.run(starting_agent=lynx, input=request)
return result.final_outputThe orchestrator decides when to call which specialist. I don’t hardcode the flow.
Feature 2: Parallel Execution
Running 7 agents sequentially would be painfully slow. The SDK supports parallel tool calls out of the box.
from agents import Agent, ModelSettings
orchestrator = Agent(
name="Keystone",
instructions="...",
tools=[...],
model_settings=ModelSettings(
parallel_tool_calls=True,
),
)Instead of letting the orchestrator call each specialist individually, I created a single tool that runs all 7 in parallel:
# Create a tool that runs all agents in parallel
@function_tool
async def run_all_specialists(request: str) -> str:
"""Run all board members in parallel."""
specialists = [lynx, wildfire, bedrock, leverage, sentinel, prism, razor]
async def run_one(agent):
result = await Runner.run(starting_agent=agent, input=request)
return result.final_output
results = await asyncio.gather(
*[run_one(a) for a in specialists],
return_exceptions=True,
)
return aggregate_results(results)
# Pass all tools to the orchestrator with parallel flag
orchestrator = Agent(
name="Keystone",
instructions="Coordinate board members to evaluate ideas.",
tools=[consult_lynx, consult_wildfire, ..., run_all_specialists],
model_settings=ModelSettings(
parallel_tool_calls=True,
),
)This cuts the wall-clock time from ~70 seconds to ~15 seconds. The specialists don’t depend on each other, so there’s no reason to wait.
Feature 3: Structured Outputs
I needed the final verdict in a predictable format, not free-form text I’d have to parse. The SDK supports Pydantic models as output types:
from pydantic import BaseModel
from agents import Agent
class BoardVerdict(BaseModel):
verdict: str # go, no_go, pivot, unclear
confidence: float
top_risks: list[str]
next_actions: list[str]
orchestrator = Agent(
name="Keystone",
instructions="...",
output_type=BoardVerdict,
)The model returns valid JSON that matches the schema. No regex parsing, no “please format as JSON” prompt hacks.
Feature 4: Guardrails
Guardrails let you validate inputs and outputs without cluttering your agent instructions. I use them to catch obviously bad requests before wasting API calls:
from agents import Agent, input_guardrail, GuardrailFunctionOutput
@input_guardrail
async def block_off_topic(ctx, agent, user_input: str):
"""Reject requests that aren't about business decisions."""
off_topic_keywords = ["write code", "debug", "fix this error"]
if any(kw in user_input.lower() for kw in off_topic_keywords):
return GuardrailFunctionOutput(
tripwire_triggered=True,
output_info="This board evaluates business decisions, not code.",
)
return GuardrailFunctionOutput(tripwire_triggered=False)
orchestrator = Agent(
name="Keystone",
instructions="...",
input_guardrails=[block_off_topic],
)If the guardrail triggers, the agent never runs. I don’t pay for tokens, and the user gets instant feedback instead of waiting 30 seconds for a rejection.
Feature 5: Streaming
Nobody wants to stare at a blank screen for 30 seconds. The SDK supports streaming so you can show progress:
from agents import Runner
result = Runner.run_streamed(agent, "Evaluate this idea...")
async for event in result.stream_events():
if event.type == "agent_updated_stream_event":
print(f"Now running: {event.new_agent.name}")
elif event.type == "raw_response_event":
# Token-by-token output
pass
final_output = result.final_outputI use this to show which specialist is currently thinking, so users know the system isn’t frozen.
Feature 6: Session Memory
The SDK has a session abstraction for conversation history. I implemented a DynamoDB backend so the board remembers past decisions:
from agents.memory import SessionABC
class DynamoDBSession(SessionABC):
async def get_items(self) -> list[dict]:
# Fetch from DynamoDB
...
async def add_items(self, items: list[dict]) -> None:
# Store to DynamoDB
...Now when I ask about a new idea, the board can reference what it told me last month. So if I ignored its advice to “validate with 5 users first,” it can call me out on it.
Demo
Here’s a quick video showing the board agent in action:
What I Learned
Parallel execution changes adoption: Users notice the difference between ~60 seconds and ~15 seconds.
Schemas unlock UI: Once outputs were consistent, building CLI and web views became straightforward.
Guardrails belong at the edge: Rejecting bad requests early saves tokens and prevents confusion.
The Result
The board now evaluates ideas in under a minute. It gives me:
- A clear GO / NO_GO / PIVOT verdict
- Confidence score based on specialist agreement
- Top 3 risks I’m probably ignoring
- Concrete next actions for the week
- A single experiment to validate assumptions
If you’re building something with multiple agents, I’d recommend checking out the OpenAI Agents SDK. I’ve tried a few frameworks before this, and the SDK’s abstractions clicked faster for me, especially the agents-as-tools pattern and the built-in streaming support.
The full code is on GitHub if you want to poke around.